2021 · Product Designer @ Gestoos
Computer vision for everyone
Computer Vision is a field of artificial intelligence focused on making machines "see." Gestoos developed technologies that can achieve better computer vision results using fewer data. However, users demanded a lot of guidance and support to reach the best performance.
I worked with a small team - a product manager, a software engineer, and an AI Tech Lead - to redesign the Creator web platform. Our goal was to make the Computer Vision training process as self-service as possible.
BEFORE

AFTER
How might we leverage Gestoos tech to empower teams without AI expertise, to implement Computer Vision solutions?
In a nutshell, there are three main steps to creating a computer vision model:
- Gather data: this is about finding or creating images representative of our use case.
- Annotate: where we highlight the bits we want the model to recognize in images and videos.
- Train model: setting parameters to split our dataset between training and validation sets, enhance data algorithmically and choose the number of times we want to show our data to the model (epochs).
To figure out how to improve the platform, we started by evaluating its current state. Heuristics evaluations and usability tests showed us that the current solution lacked a structured process, and users often felt helpless on how to improve results.
We regularly heard users asking themselves:
- What should I do next?
- Do I have enough data?
- Is my data good enough?
- How can I improve this model?
- Add more data?
- Refine the data annotations?
- Choose different training parameters or base model?

Old platform flow
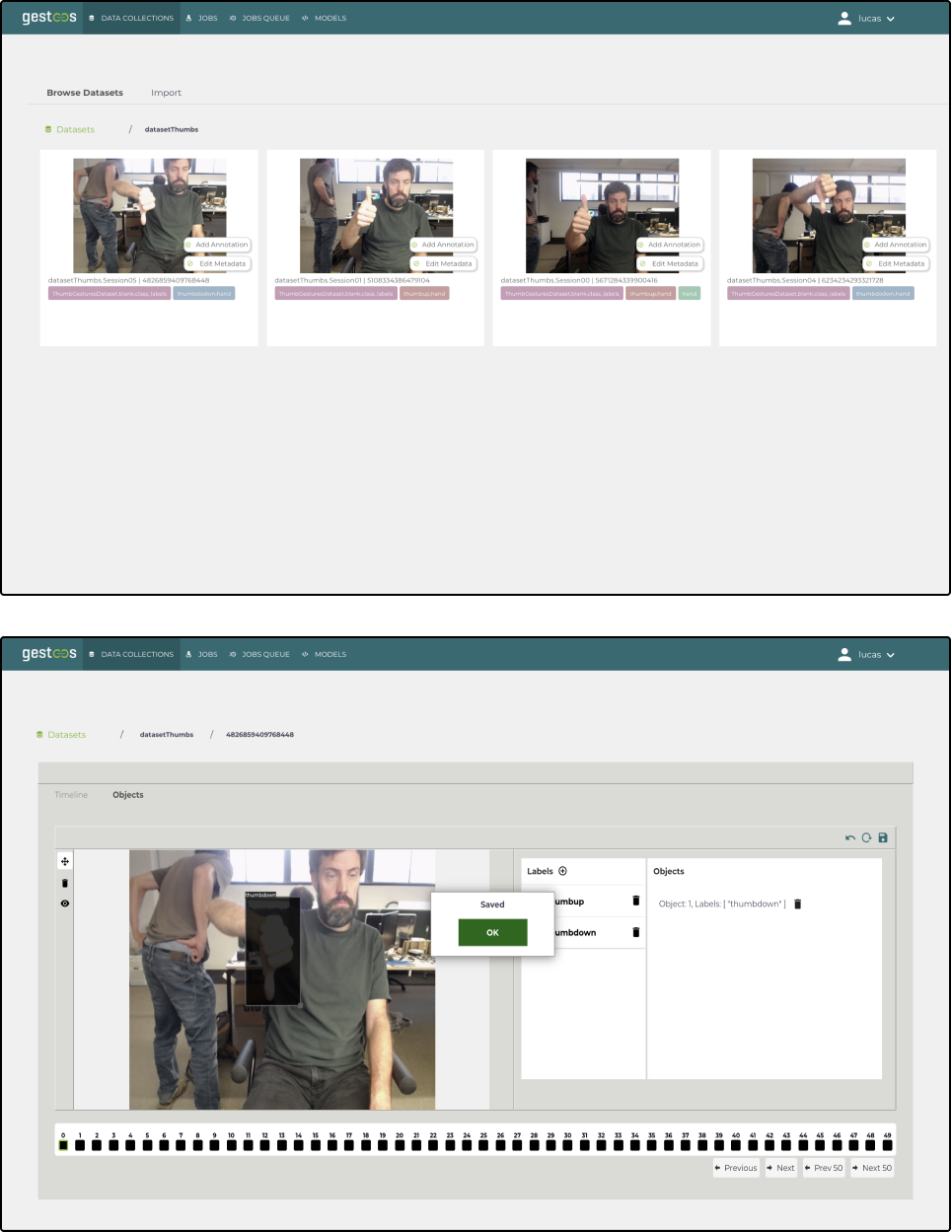
In the old platform structure, a Datasets page gathered all user's datasets independent of the use case. It also had a Models page that listed together all models the user trained, with no regard for the use case or the dataset it used. This structure was confusing and made it hard to iterate on models to improve them.

Old platform - User selecting datasets for model training.
Talking to users
Our users were mainly part of small teams working on research and development initiatives willing to bring cutting-edge technology into their products.
They wanted to:
- Implement gestural interactions into displays and monitors
- Analyze human behavior to prevent dangerous situations
- Increase safety with intelligent surveillance
For them, computer vision is only a small piece of much bigger projects. As they don't have AI expertise, they want the best results with the least effort - without running into any privacy and security risks.
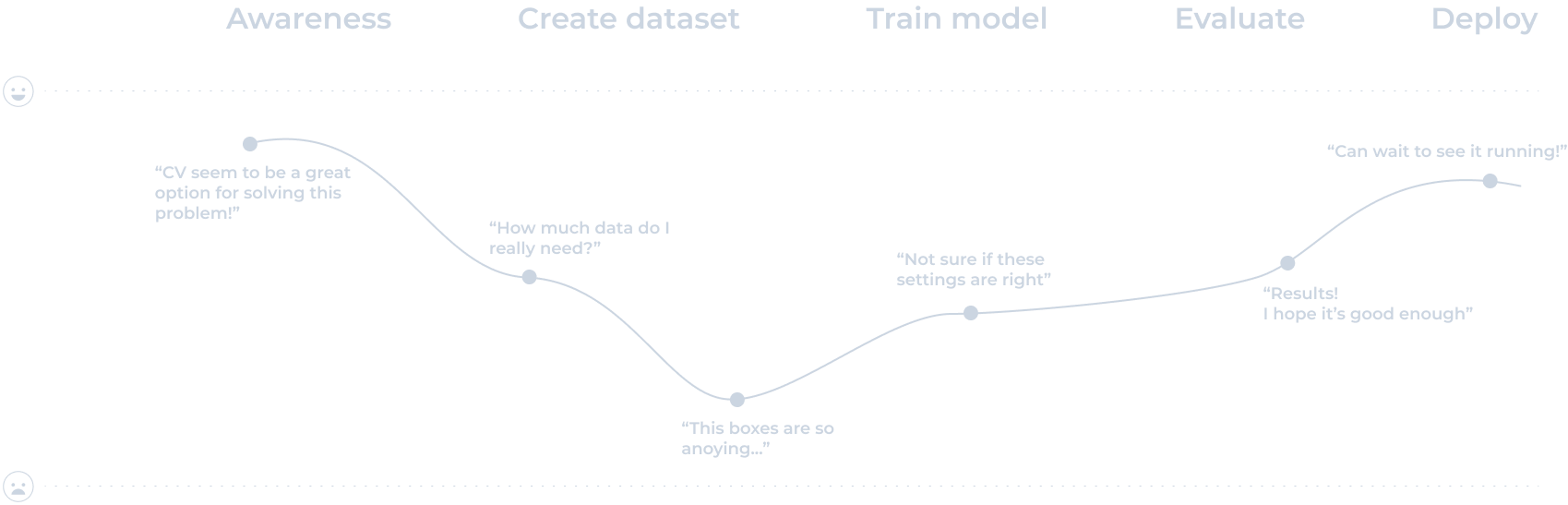
User journey
Users' goal
Use computer vision to improve product offerings and interactions without developing deep artificial intelligence expertise.
Needs
- Understand if what they are trying to do is feasible
- Best computer vision results with the least effort
- Privacy and security soundness
Design principles
Based on our learnings and taking into account Gestoos vision, we defined three design principles to guide our work:

It Guides You
Users should know where they are in the process and what next steps will help them achieve their goals.

Progressive complexity
Most complex processes will take place in the background, allowing users to focus on their use case.

Gives you confidence
Users should feel good about what they've achieved and confident to apply results in the real world.
Exploring alternatives
After evaluating some design options, we started teasing the idea of having a project structure to unify the process and guide the user on the steps to train a new computer vision model.

Wireframe: structure + steps
However, the steps felt too rigid. To reach good results, users must iterate on their models. They may need to add new data, adjust labels and annotations, train with new parameters and compare results - in no specific order.

New plarform flow
Given that, we redesigned the project to have two main sections. In the Dataset section, users import data, annotate and have an overview of the dataset. While in the Models section, users can train or improve models, evaluate and compare performance, and finally export to integrate into their solution.
The Solution
At the start, users go through a project setup where they can learn more about the process and choose the first settings: the model type and labels.

Project setup
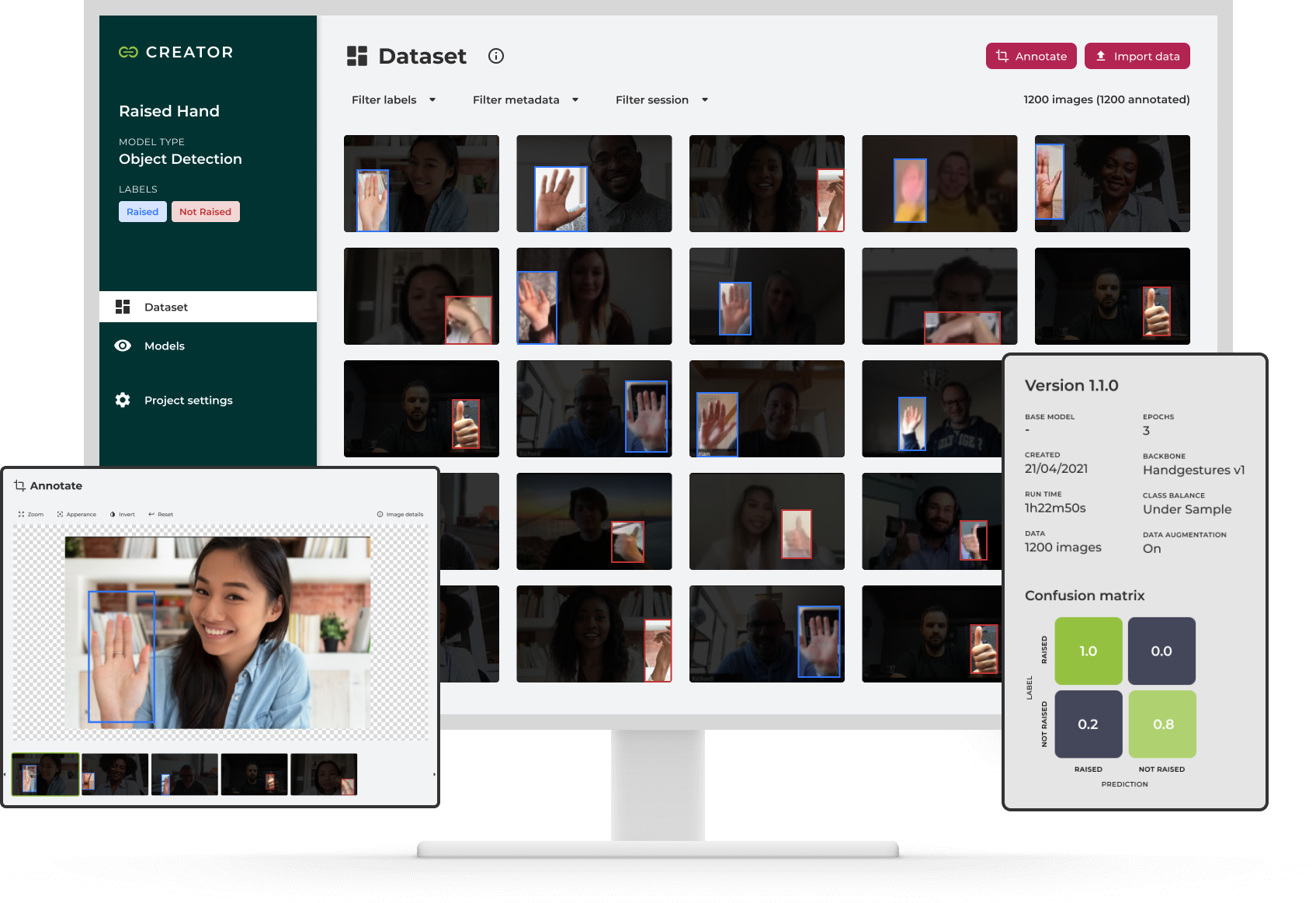
Once the project is ready, users get to the Dataset page, where they can manage all the project data. They begin by uploading new data or importing it from other projects in the platform. It's also possible to define metadata to the imports to help filter files later.

Dataset - Import data options
Next, users annotate files using the initially set labels and then analyze the work for inconsistencies using filters and the dataset overview. We want to help people become efficient creators of high-quality datasets.

Data annotation

Annotated dataset
After preparing the project dataset, users can start training their models. We now provide a default training option that automatically sets most of the training parameters for the user. This option could hardly get the best possible results. But our goal here is to simplify and help them progress by achieving good enough results to validate their ideas and provide a sense of accomplishment. Later on, users can improve the initial models using custom training parameters.
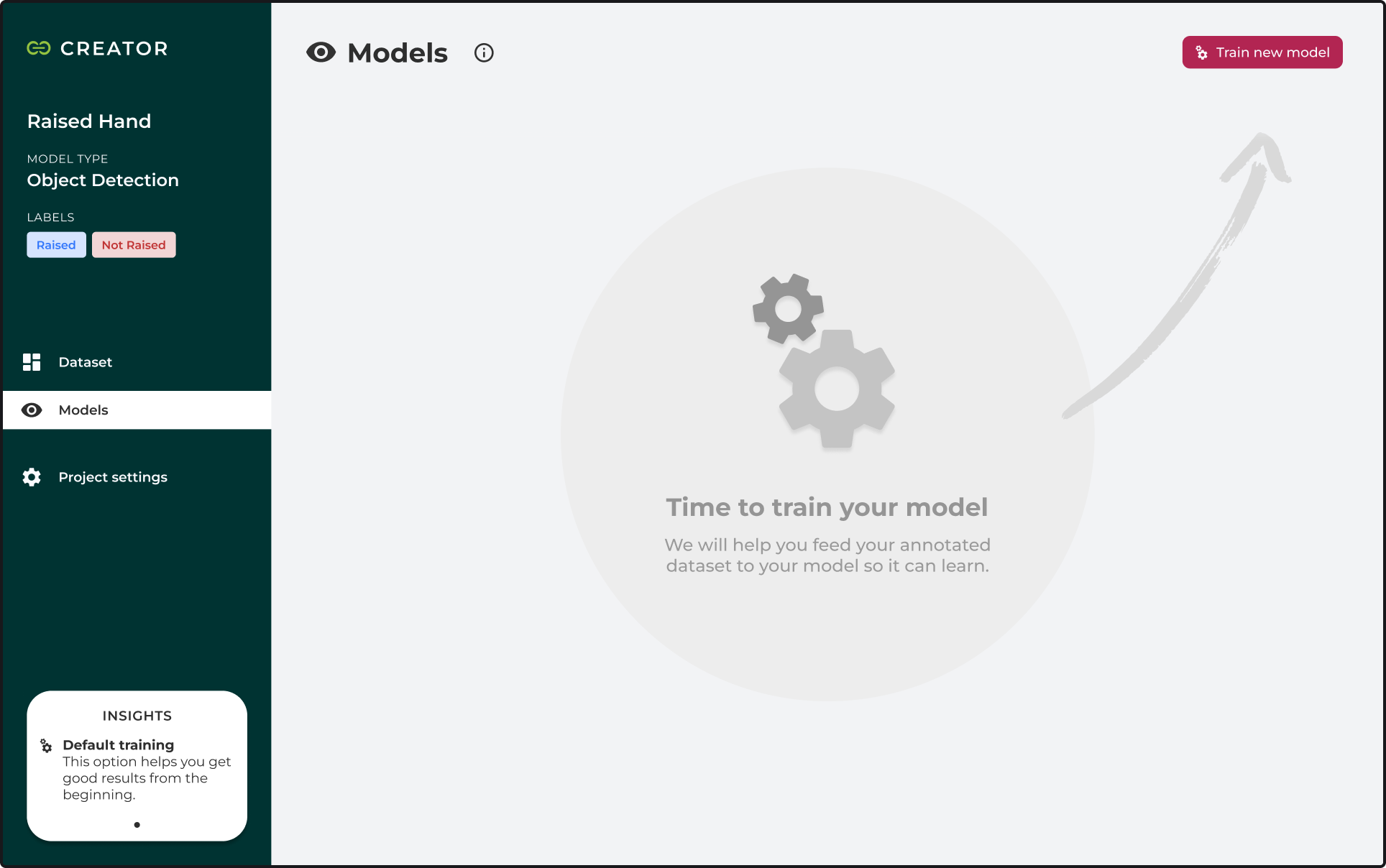
Models section - empty state

Training a new model
An essential part of developing computer vision models is to understand their shortcomings. The confusion matrix gives insights into where the model's prediction does not match the annotation. Filtering the predictions through the matrix lets users evaluate if there are any annotations problems. If there isn't any issue, users can look for patterns where the model is making mistakes and diversify the dataset to create a more generic agent.

Evaluate model performance
Results
We ran usability tests on the new prototype and found that people quickly understood how to navigate the training process. They had no problems moving from preparing datasets to training computer vision models and got thrilled to interact with the model performance in the confusion matrix.
It was also interesting to see how people received the Insights feature - an AI assistant that provides contextual information about potential data biases and training parameter adjustments - users reported being more confident to move forward with the assistance. However, we were only able to test its receptiveness now. We still need to study how helpful it can genuinely be.

Insights - AI assistant
Overall, the new project structure achieves our goal of empowering people to create high-performance computer vision models on their own. Having that said, diving deeper into each feature can still improve the process efficiency and make it more enjoyable.